
OCR (Text Detection)
Try to use OCR.
It is a smart labeling model that performs OCR (Optical Character Recognition) tasks that can recognize diverse languages.
It is available when the task type is set to Polygon in the project's labeling settings.
A method to use OCR Smart Labeling
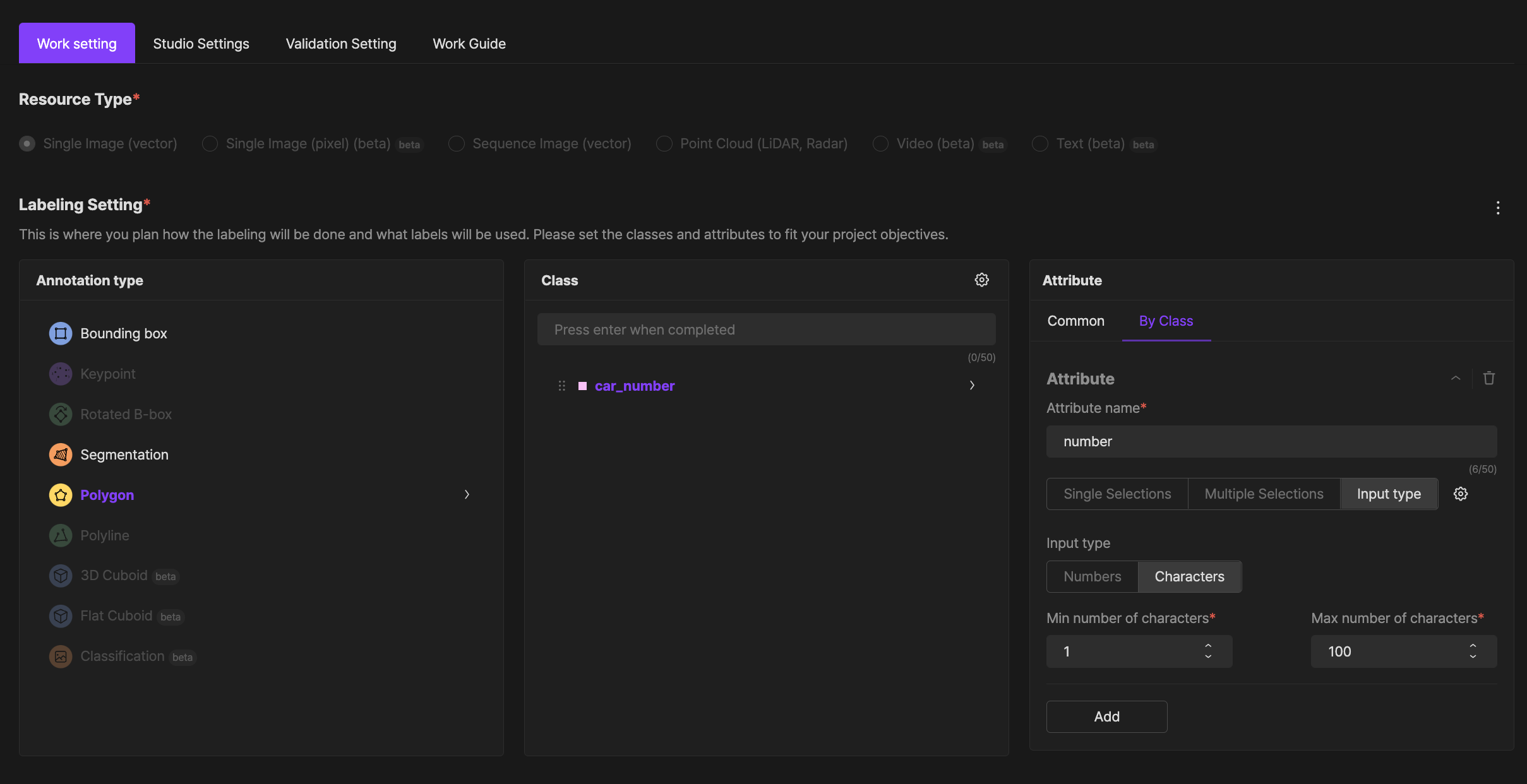
Example of OCR project setting
1. Setting up a class
- Create a project by setting the "Task type" to
"Polygon"in the project's"Labeling settings". - After selecting the corresponding class, and then add
"Attributes by each class". - After entering the Attribute name that you want to use, set "Attribute entering method" to
"entering type". - Put "entering type" as "characters", "Minimum number of entering characters" as 1, and "Maximum number of entering characters" as 1,000.
- Click the
"completion"button at the bottom right.
2. Setting up smart labeling inference
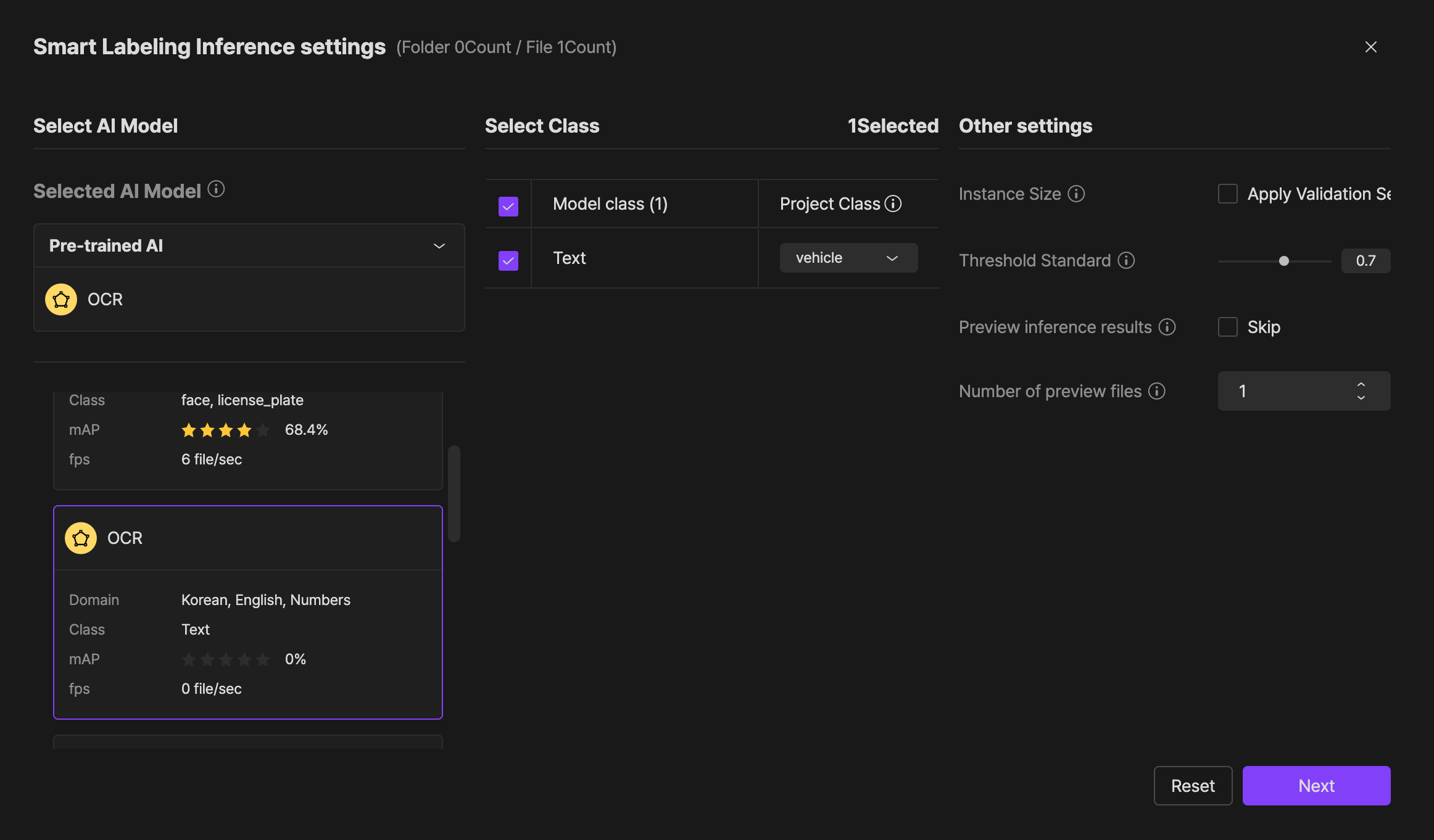
- After selecting the folder or file that you want to perform OCR-Smart Labeling in the dataset of the project and then click "Smart labeling".
- At
"Select a task AI model", select the pre-set model that corresponds to the language that you want.
- OCR: Korean/English/Numeric
- OCR (Japanese): Japanese/English
- OCR (Russian): Russian
- 'Set the class for that you set
"Attribute"at STEP-1 to match the "text" class of the Pre-set Model. - At
"setting others", set the "Threshold" standard value to the minimum value of "0.2". - By clicking the
"Completion"button at the bottom right, proceed with OCR Smart Labeling.
Working on OCR Smart Labeling

Example of applying OCR-Smart Labeling
- A square box in the form of the "Polygon" will be created in the area that has letters.
- Within the generated "Polygon" area, the value which corresponds to the "Attribute Name" designated at the project's "Labeling Settings" is characters inferred by the OCR model will be entered automatically.
- Workers will inspect or work again on the results of the OCR model inference.
The extent of the performance guarantee of Smart Labeling
- Information about images
- Resolution: HD or higher
- Minimum size: If the height of the text is less than 8px, the performance of the OCR model will be degraded.
- etc.
- For OCR models, Custom Model learning is not supported.
If you have any other inquiries, please get in touch with us at [email protected]